Konfigurationsfehler legt Microsoft Azure stundenlang lahm
Nur eine Woche nach dem großen Ausfall bei AWS erwischte es am Mittwochabend die Microsoft-Kunden. Aufgrund einer "unbeabsichtigten Konfigurationsänderung" kam es weltweit zu erheblichen Problemen mit Azure, durch die Dienste von Microsoft und anderen Unternehmen mehrere Stunden lang nicht mehr verfügbar waren.
Während Amazon, seine Partner, Kunden und die Versicherer noch dabei sind, den umfassenden Ausfall bei AWS in der vergangenen Woche zu analysieren und verarbeiten (siehe: 7 Lehren aus dem AWS-Ausfall: Kosten und Konsequenzen), ging am Mittwochabend der nächste Hyperscaler in zeitweise die Knie. Ab kurz vor 17 Uhr MEZ konnten Kunden weltweit plötzlich nicht mehr auf Azure-basierende Dienste zugreifen. Neben diversen konzerneigenen Microsoft-365-Produkten und -Diensten wie Entra, Purview, Defender, Intune und der Xbox-Plattform betraf das auch die Onlinedienste zahlreicher Unternehmenskunden wie etwa von Händlern, Gastronomieketten und Fluggesellschaften.
Schon kurz darauf tauchte eine entsprechende Meldung auf der Online-Statusseite von Azure auf. Darin erklärte Microsoft, dass eine gegen 17 Uhr registrierte Störung beim Cloud Content Delivery Network (CDN) Azure Front Door (AFD) für den Ausfall einiger Dienste verantwortlich sei und zu Problemen mit der Netzwerkinfrastruktur führe. Ähnlich wie bei AWS spielte also auch hier das DNS-Umfeld, das nicht umsonst als des Admins liebster Sündenbock gilt, eine Rolle.
"Wir haben mit dem Deployment unserer ‚letzten als funktionierend bekannten‘ Konfiguration begonnen", teilte Microsoft am Mittwoch um 19:11 Uhr auf der Azure-Statusseite mit. "Die vollständige Bereitstellung wird voraussichtlich in etwa 30 Minuten abgeschlossen sein. Ab diesem Zeitpunkt werden die Kunden erste Anzeichen einer Wiederherstellung feststellen können. Sobald dies abgeschlossen ist, besteht der nächste Schritt darin, mit der Wiederherstellung der Knoten zu beginnen, während wir den Datenverkehr über diese funktionierenden Knoten leiten."
Ausfall von Microsoft Azure reißt weitere Dienste mit
Ein Microsoft-Sprecher bestätigte CRN am Mittwoch in einer E-Mail das AFD-Problem als Ursache und empfahl: "Kunden sollten weiterhin ihre Service Health Alerts überprüfen. Die neuesten Informationen zu diesem Problem finden Sie auf der Azure-Statusseite."
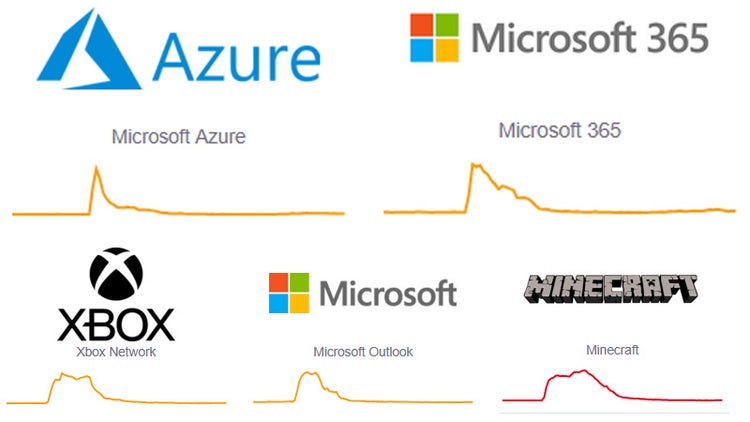
Die Website Downdetector (in Deutschland Allestörungen), die Informationen über entsprechende Ausfälle sammelt und aufzeichnet, verzeichnete am Mittwoch kurz nach dem Auftreten der Probleme einen steilen Anstieg bei den meisten betroffenen Angeboten und Diensten, der jedoch in den meisten Fällen auch recht schnell wieder abflaute.
- Bei Azure wurde in den USA schnell ein Peak-Wert von rund 20.000 Meldungen erreicht, nach etwa eineinhalb Stunden waren es derer noch knapp 3.000.
- Microsoft 365 erreichte einen Spitzenwert von fast 12.000 Meldungen in den USA und von knapp 900 in Deutschland. Innerhalb von etwas mehr als einer Stunde gingen diese Zahlen auf etwa 4.000 (USA) und gut 700 (D) zurück.
- Für den Microsoft Store wurden maximal etwa 3.200 Hinweise auf Störungen verzeichnet, die sich innerhalb von etwa 90 Minuten halbierten.
- Bei Outlook gab es initial zwar nur etwa 2.000 Störungsmeldungen, allerdings blieb dieses Niveau mehr als eine Stunde lang stabil.
Zu den betroffenen Azure-Kunden mit in Mitleidenschaft gezogenen eigenen Services zählte unter anderem Alaska Airlines. Die Fluggesellschaft machte den Ausfall von Azure in einem X-Beitrag am Mittwoch für die Störung der Websites von Alaska und seiner Marke Hawaiian Airlines sowie anderer Systeme wie des Online-Check-Ins verantwortlich. "Wir entschuldigen uns für die Unannehmlichkeiten und bedanken uns für Ihre Geduld, während wir dieses Problem beheben", erklärte Alaska und bat die Passagiere, frühzeitig zu Abflügen zu erscheinen, um beim Service-Personalk vor Ort einchecken zu können.
Der Vorfall unterstreicht erneut zwei wichtige Punkte, die auch im Zusammenhang mit dem AWS-Ausfall wieder verstärkt in den Fokus gerückt sind. Erstens ist das die Aussage des ehemaligen AWS- und Google-Topmanagers Debanjan Saha gegenüber CRN, der es mit Blick auf die Systeme der Hyperscaler "angesichts ihrer enormen globalen Reichweite und der Komplexität" für "bemerkenswert" hält, "dass großflächige Störungen wie diese so selten sind". Dass es in so kurzem Abstand gleich zwei der Cloud-Giganten trifft, bestätigt unmittelbar seine Prognose, "Die Frage ist nicht ob, sondern wann". Zweitens ist der Vorfall Wind in den Segeln der europäischen Souveränitätsbewegung, da er unterstreicht, dass weder die Größe der US-Hyperscaler noch eine Multi-Cloud ein wirksamer Schutz vor solchen Szenarien sind.
AFD verursacht sieben Stunden Ausfallzeit
Im Rahmen seiner Abhilfemaßnahmen hat Microsoft das Azure-Verwaltungsportal vom AFD getrennt, um einen besseren Zugriff zu ermöglichen, und die Benutzer aufgefordert, direkt auf das Portal zuzugreifen. Der Anbieter empfahl den Benutzern zudem, Failover-Strategien mit Azure Traffic Manager zu implementieren.
Während die Maßnahmen zur Behebung liefen, wurden Änderungen an der Kundenkonfiguration blockiert. Am Mittwochabend um 19:11 Uhr konnte Microsoft noch keinen voraussichtlichen Zeitpunkt für die vollständige Behebung nennen. Die Statusseite zeigte zu diesem Zeitpunkt, dass Azure Front Door in mehreren Azure-Regionen funktionierte, darunter Ost-USA, Ost-USA 2, Süd-Zentral-USA, Nordeuropa, Westeuropa und Zentralfrankreich. Der Anbieter wies auf der Statusseite darauf hin, dass die Erweiterungen des Azure-Verwaltungsportals ordnungsgemäß funktionierten, dass es aber bei Endpunkten im Zusammenhang mit dem Marketplace und anderen Endpunkten zu Problemen beim Laden kommen könnte.
Auf einer separaten Online-Statusseite für M365 teilte Microsoft mit, dass Benutzer nicht auf das Microsoft 365-Administratorcenter zugreifen können und es zu Verzögerungen bei anderen M365-Diensten kommen kann. Laut Angaben des Anbieters hatten Administratoren auch Probleme beim Zugriff auf einige Funktionen von Microsoft Entra, Microsoft Purview, Microsoft Defender, Microsoft Power Apps und Microsoft Intune. Auch Add-Ins und die Netzwerkverbindung in Outlook schienen gestört zu sein.
Microsoft veröffentlichte am Mittwoch um 17:21 Uhr eine Meldung auf X, ehemals Twitter, in der zunächst ein Problem mit den Azure Front Door-Diensten bestätigt und davor gewarnt wurde, dass es für Benutzer zu Latenzzeiten und zeitweiligen Fehlschlägen bei Anfragen kommen könnte. Fünf Minuten später folgte ein weiterer Beitrag, in dem Microsoft auf Probleme beim Zugriff auf Microsoft 365-Dienste und das Microsoft 365-Administratorcenter hinwies. Um 18:19 Uhr wurde ein weiterer Beitrag veröffentlicht, in dem der Hersteller darauf hinwies, dass eine kürzlich vorgenommene Konfigurationsänderung an einem Teil von Azure möglicherweise Probleme mit M365 verursache. Die Online-Cloud-Statusseite von Microsoft war während des Ausfalls zeitweise nicht verfügbar. Um 18:57 Uhr gab Microsoft dann auf X bekannt, dass es die Einführung der betroffenen Konfigurationsänderung gestoppt hat.
"Wir leiten den Datenverkehr weiterhin von der betroffenen Infrastruktur weg, um die Verfügbarkeit der Dienste wiederherzustellen", erklärte der Anbieter. "Parallel dazu arbeiten wir daran, die betroffene Infrastruktur in einen früheren Zustand zurückzuversetzen." Später aktualisierte Microsoft auch seine Online-Azure-Statusseite und gab bekannt, dass die Wiederherstellung voraussichtlich bis Donnerstag um 00:20 Uhr, also gut sieben Stunden nach dem Beginn des Ausfalls, erfolgen werde. Das scheint nach bisherigem Ermessen gelungen zu sein.
Microsoft aktualisierte in dieser Zeit beständig seine Liste der betroffenen Azure-Dienste und fügte App Service, Azure Active Directory B2C, Azure Communication Services, Azure Databricks, Azure Healthcare APIs, Azure Maps, Azure Portal, Azure SQL Database, Container Registry, Media Services, Microsoft Defender External Attack Surface Management, Microsoft Entra ID, Microsoft Purview, Microsoft Sentinel, Video Indexer und Virtual Desktop hinzu.
Teile dieses Textes erschienen zuerst bei unserer Schwester-Publikation crn.com
CRN-Newsletter beziehen und Archiv nutzen - kostenlos: Jetzt bei der CRN Community anmelden